《浏览器工作原理与实践》笔记之从堆栈空间看闭包过程
《浏览器工作原理与实践》笔记之从堆栈空间看闭包过程
基础
我们先看下面的代码
function foo(){
var a = "极客时间"
var b = a
var c = {name:"极客时间"}
var d = c
}
foo()执行第 4 行代码,由于 JavaScript 引擎判断右边的值是一个引用类型,这时候处理的情况就不一样了,JavaScript 引擎并不是直接将该对象存放到变量环境中,而是将它分配到堆空间里面,分配后该对象会有一个在“堆”中的地址,然后再将该数据的地址写进 c 的变量值,最终分配好内存的示意图如下所示:
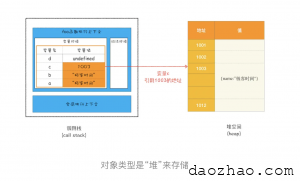
我们知道原始类型的数据值都是直接保存在“栈”中的,引用类型的值是存放在“堆”中的。
不过你也许会好奇,为什么一定要分“堆”和“栈”两个存储空间呢?所有数据直接存放在“栈”中不就可以了吗?
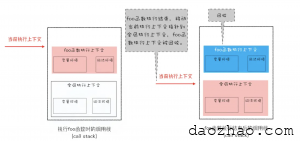
这是因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。比如文中的 foo 函数执行结束了,JavaScript 引擎需要离开当前的执行上下文,只需要将指针下移到上个执行上下文的地址就可以了,foo 函数执行上下文栈区空间全部回收,具体过程你可以参考下图:
进阶
有了上面基础,我们再来看下闭包 先看下面的代码
function foo() {
var myName = "极客时间"
let test1 = 1
const test2 = 2
var innerBar = {
setName:function(newName){
myName = newName
},
getName:function(){
console.log(test1)
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName("极客邦")
bar.getName()
console.log(bar.getName())我们已经知道由于变量 myName、test1、test2 都是原始类型数据,所以在执行 foo 函数的时候,它们会被压入到调用栈中;当 foo 函数执行结束之后,调用栈中 foo 函数的执行上下文会被销毁,其内部变量 myName、test1、test2 也应该一同被销毁。
我们还知道当 foo 函数的执行上下文销毁时,由于 foo 函数产生了闭包,所以变量 myName 和 test1 并没有被销毁,而是保存在内存中,那么应该如何解释这个现象呢?
- 当 JavaScript 引擎执行到 foo 函数时,首先会编译,并创建一个空执行上下文。
- 在编译过程中,遇到内部函数 setName,JavaScript 引擎还要对内部函数做一次快速的词法扫描,发现该内部函数引用了 foo 函数中的 myName 变量,由于是内部函数引用了外部函数的变量,所以 JavaScript 引擎判断这是一个闭包,于是在堆空间创建换一个“closure(foo)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存 myName 变量。
- 接着继续扫描到 getName 方法时,发现该函数内部还引用变量 test1,于是 JavaScript 引擎又将 test1 添加到“closure(foo)”对象中。这时候堆中的“closure(foo)”对象中就包含了 myName 和 test1 两个变量了。
- 由于 test2 并没有被内部函数引用,所以 test2 依然保存在调用栈中。
通过上面的分析,我们可以画出执行到 foo 函数中“return innerBar”语句时的调用栈状态,如下图所示:
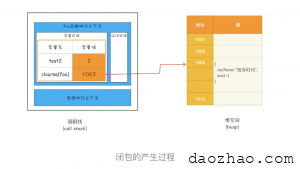
从上图你可以清晰地看出,当执行到 foo 函数时,闭包就产生了;当 foo 函数执行结束之后,返回的 getName 和 setName 方法都引用“clourse(foo)”对象,所以即使 foo 函数退出了,“clourse(foo)”依然被其内部的 getName 和 setName 方法引用。所以在下次调用bar.setName或者bar.getName时,创建的执行上下文中就包含了“clourse(foo)”。
总的来说,产生闭包的核心有两步:第一步是需要预扫描内部函数;第二步是把内部函数引用的外部变量保存到堆中。
- 分类:
- Web前端
相关文章
《浏览器工作原理与实践》笔记之从输入URL到页面展示发生了什么
从输入URL到页面展示发生了什么,大致过程如下 一、用户输入 浏览器进程接收到用户输入的 URL 请求,浏览器进程便将该 URL 转发给网络进程。 当用户输入关键字并键入回车之 阅读更多…
《浏览器工作原理与实践》笔记之渲染流程
由于渲染机制过于复杂,所以渲染模块在执行过程中会被划分为很多子阶段,输入的 HTML 经过这些子阶段,最后输出像素。我们把这样的一个处理流程叫做渲染流水线,其大致流程如下图所示: 按照渲染的 阅读更多…
《浏览器工作原理与实践》笔记之浏览器进程
浏览器从单进程浏览器时代进入多进程时代 Q1:最新的浏览器架构图 Q2:浏览器打开一个tab页,一般会有几个进程? 浏览器主进程 GPU进程 网络进程 阅读更多…
《浏览器工作原理与实践》笔记之垃圾回收
先了解下垃圾回收领域的重要术语——代际假说和分代收集。 代际假说 第一个是大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问; 第二个是不死的对 阅读更多…
《浏览器工作原理与实践》笔记之数据包传输
从 数据包如何送达主机 、 主机如何将数据包转交给应用 和 数据是如何被完整地送达应用程序 这三个角度来为你讲述数据的传输过程。 IP:把数据包送达目的主机 下面我们一起来看下一个数 阅读更多…
