《浏览器工作原理与实践》笔记之HTTP2
《浏览器工作原理与实践》笔记之HTTP2
HTTP/2 的多路复用
前面我们分析了 HTTP/1.1 所存在的一些主要问题:慢启动和 TCP 连接之间相互竞争带宽是由于 TCP 本身的机制导致的,而队头阻塞是由于 HTTP/1.1 的机制导致的。那么该如何去解决这些问题呢?
虽然 TCP 有问题,但是我们依然没有换掉 TCP 的能力,所以我们就要想办法去规避 TCP 的慢启动和 TCP 连接之间的竞争问题。
基于此,HTTP/2 的思路就是一个域名只使用一个 TCP 长连接来传输数据,这样整个页面资源的下载过程只需要一次慢启动,同时也避免了多个 TCP 连接竞争带宽所带来的问题。
另外,就是队头阻塞的问题,等待请求完成后才能去请求下一个资源,这种方式无疑是最慢的,所以 HTTP/2 需要实现资源的并行请求,也就是任何时候都可以将请求发送给服务器,而并不需要等待其他请求的完成,然后服务器也可以随时返回处理好的请求资源给浏览器。
所以,HTTP/2 的解决方案可以总结为:一个域名只使用一个 TCP 长连接和消除队头阻塞问题。可以参考下图:
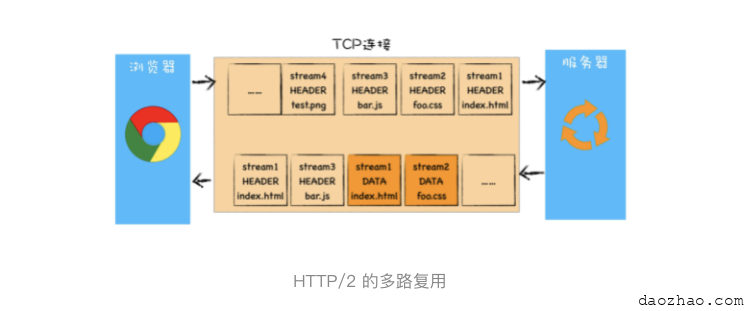
该图就是 HTTP/2 最核心、最重要且最具颠覆性的多路复用机制。从图中你会发现每个请求都有一个对应的 ID,如 stream1 表示 index.html 的请求,stream2 表示 foo.css 的请求。这样在浏览器端,就可以随时将请求发送给服务器了。
服务器端接收到这些请求后,会根据自己的喜好来决定优先返回哪些内容,比如服务器可能早就缓存好了 index.html 和 bar.js 的响应头信息,那么当接收到请求的时候就可以立即把 index.html 和 bar.js 的响应头信息返回给浏览器,然后再将 index.html 和 bar.js 的响应体数据返回给浏览器。之所以可以随意发送,是因为每份数据都有对应的 ID,浏览器接收到之后,会筛选出相同 ID 的内容,将其拼接为完整的 HTTP 响应数据。
多路复用的实现
现在我们知道为了解决 HTTP/1.1 存在的问题,HTTP/2 采用了多路复用机制,那 HTTP/2 是怎么实现多路复用的呢?
你可以先看下面这张图:
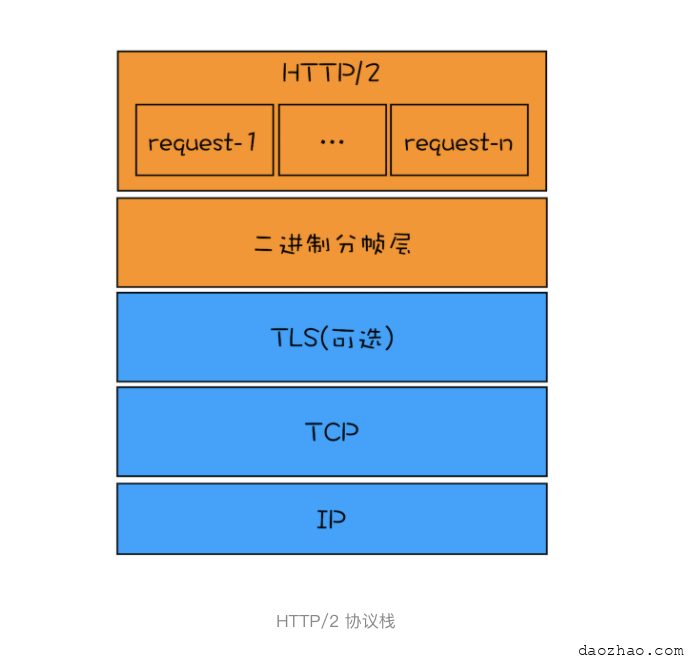
HTTP/2 协议栈从图中可以看出,HTTP/2 添加了一个二进制分帧层,那我们就结合图来分析下 HTTP/2 的请求和接收过程。
- 首先,浏览器准备好请求数据,包括了请求行、请求头等信息,如果是 POST 方法,那么还要有请求体。
- 这些数据经过二进制分帧层处理之后,会被转换为一个个带有请求 ID 编号的帧,通过协议栈将这些帧发送给服务器。
- 服务器接收到所有帧之后,会将所有相同 ID 的帧合并为一条完整的请求信息。
- 然后服务器处理该条请求,并将处理的响应行、响应头和响应体分别发送至二进制分帧层。
- 同样,二进制分帧层会将这些响应数据转换为一个个带有请求 ID 编号的帧,经过协议栈发送给浏览器。浏览器接收到响应帧之后,会根据 ID 编号将帧的数据提交给对应的请求。
从上面的流程可以看出,通过引入二进制分帧层,就实现了 HTTP 的多路复用技术。
HTTP/2 其他特性
通过上面的分析,我们知道了多路复用是 HTTP/2 的最核心功能,它能实现资源的并行传输。多路复用技术是建立在二进制分帧层的基础之上。其实基于二进制分帧层,HTTP/2 还附带实现了很多其他功能,下面我们就来简要了解下。
1. 可以设置请求的优先级
我们知道浏览器中有些数据是非常重要的,但是在发送请求时,重要的请求可能会晚于那些不怎么重要的请求,如果服务器按照请求的顺序来回复数据,那么这个重要的数据就有可能推迟很久才能送达浏览器,这对于用户体验来说是非常不友好的。为了解决这个问题,HTTP/2 提供了请求优先级,可以在发送请求时,标上该请求的优先级,这样服务器接收到请求之后,会优先处理优先级高的请求。
2. 服务器推送
除了设置请求的优先级外,HTTP/2 还可以直接将数据提前推送到浏览器。你可以想象这样一个场景,当用户请求一个 HTML 页面之后,服务器知道该 HTML 页面会引用几个重要的 JavaScript 文件和 CSS 文件,那么在接收到 HTML 请求之后,附带将要使用的 CSS 文件和 JavaScript 文件一并发送给浏览器,这样当浏览器解析完 HTML 文件之后,就能直接拿到需要的 CSS 文件和 JavaScript 文件,这对首次打开页面的速度起到了至关重要的作用。
3. 头部压缩
无论是 HTTP/1.1 还是 HTTP/2,它们都有请求头和响应头,这是浏览器和服务器的通信语言。HTTP/2 对请求头和响应头进行了压缩,你可能觉得一个 HTTP 的头文件没有多大,压不压缩可能关系不大,但你这样想一下,在浏览器发送请求的时候,基本上都是发送 HTTP 请求头,很少有请求体的发送,通常情况下页面也有 100 个左右的资源,如果将这 100 个请求头的数据压缩为原来的 20%,那么传输效率肯定能得到大幅提升。
- 分类:
- Web前端
相关文章
《浏览器工作原理与实践》笔记之HTTP、TCP、DNS
因为浏览器使用 HTTP 协议作为应用层协议,用来封装请求的文本信息;并使用 TCP/IP 作传输层协议将它发到网络上,所以在 HTTP 工作开始之前,浏览器需要通过 TCP 与服务器建立连接。也就 阅读更多…
《浏览器工作原理与实践》笔记之HTTP 请求和响应流程
浏览器端发起 HTTP 请求流程 构建请求 浏览器构建请求报文信息,构建好后,浏览器准备发起网络 请求行 GET /index.html HTTP1.1 发送 请求行 ,就是 阅读更多…
《浏览器工作原理与实践》笔记之HTTP诞生到HTTP 1.1
HTTP 0.9 HTTP协议最早的版本是0.9版本,于1991年提出,其需求很简单——用来在网络之间传递 HTML 超文本的内容。 完整的请求流程如下: 因为 HTTP 都是基于 TC 阅读更多…
curl获取https开头的url的内容
平时我们用curl一般都获取http页面的内容,代码如下 $theurl= "http://www.xx.com"; $_data = array( 'clie 阅读更多…
使用app的华为应用内支付服务还是小心为上,2023年了还有人在支付场景使用http。。。
近期查看邮件的时候发现华为开发者联盟发的一封邮件,大致意思就是出于安全考虑,将于2023年10月1日全面限制应用内支付服务使用HTTP回调地址了。 众所周知HTTP协议以明文方式发送内容,不提供 阅读更多…
《浏览器工作原理与实践》笔记之HTTP诞生到HTTP 1.1
HTTP 0.9 HTTP协议最早的版本是0.9版本,于1991年提出,其需求很简单——用来在网络之间传递 HTML 超文本的内容。 完整的请求流程如下: 因为 HTTP 都是基于 TC 阅读更多…