自定义分词起始规则实现关键词全词高亮项目实战(全语种通吃)
自定义分词起始规则实现关键词全词高亮项目实战(全语种通吃)
背景
最近有BU给我们这边提了一个需求,希望我们能改进现有的内容关键词匹配功能,希望能支持英文的全词匹配。
目前前端页面是会对后台配置的关键词进行高亮显示的,只不过算是模糊匹配了,也就是说如果关键词配的是book,内容中的booked中的book也会高亮,而这并不是BU希望的。
现状
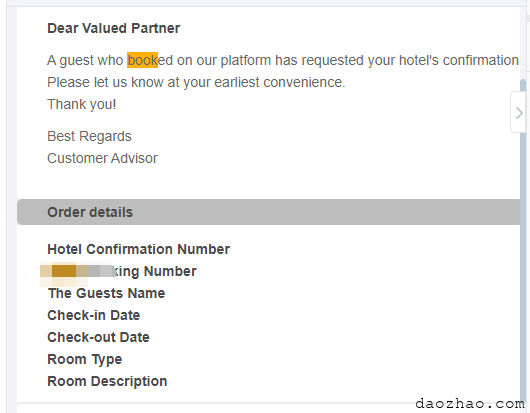
我看了下原来高亮功能的具体实现
export function escapeHtml(text) {
var map = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
"'": ''',
};
return text.replace(/[&<>"']/g, function(m) {
return map[m];
});
}
// 搜索html关键字并高亮
export function htmlKeyWordHighlight(parentNode, keyWards, color = 'yellow') {
if (keyWards === void 0 || !parentNode) return;
for (var i = 0; i < parentNode.childNodes.length; i++) {
var child = parentNode.childNodes[i];
if (child.nodeType == 3 && child.data.indexOf(keyWards) != -1) {
var newChild = document.createElement('span');
var tagStripper = new RegExp(keyWards, 'g');
newChild.innerHTML = escapeHtml(child.data).replace(
tagStripper,
`<span style="background: ${color};">` + keyWards + '</span>',
);
parentNode.replaceChild(newChild, child);
} else {
htmlKeyWordHighlight(child, keyWards, color);
}
}
}
打出这keyWards的我猜测用的编辑器多半是vscode或者是个心态特别好的老哥,但凡是idea系列的那波浪线就容易让人有强迫症。
用法大致就是这样htmlKeyWordHighlight(document.body, "book","#FFB10A"),这样就会把body上所有包含book的字符串高亮起来了。
方法里面执行的是字符串的replace操作,以book的替换为例,实际执行的是"A guest who booked xxx".replace(/book/g, "***")操作,此时是不会顾及是否是全词匹配的,只要匹配上都会替换的。
常规解决方案——正则表达式\b
既然之前用的是正则表达式,我们优先考虑能不能优化下正则表达式来完成需求。
如果只是想简单的应对英文的话,我们用上正则表达式的元字符\b就行,它代表着单词的开头或结尾,也就是单词的分界处。
更精确的说法,\b匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在) \w,我们可以简单的理解\b等识别出一个分词的开始和结束。
很符合英文单词全词匹配,可以测试一下。
"A guest who booked xxx".replace(/\bbook\b/g, "***")。
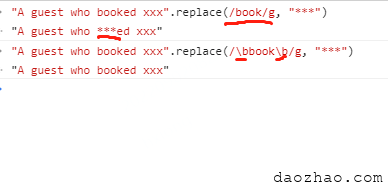
带不带\b效果很明显,客户提的需求也就算满足了。
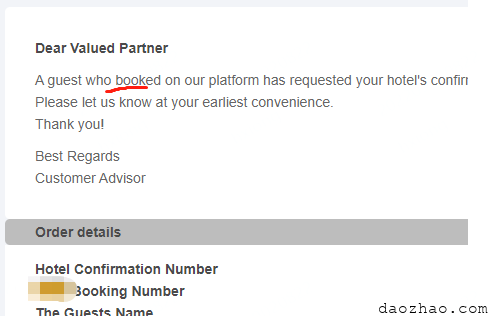
终极解决方案——逐词匹配
如果想对中文等非英文语种进行类似的分词用\b就不行了,我们也没法更换\b的识别机制。
我们试着自己实现下,对潜在的目标文本进行逐词匹配就行。
记得首先要确定潜在目标文本,缩小逐词匹配的范围。
export function htmlKeyWordHighlight(parentNode, keyword, color = 'yellow') {
if (keyword === void 0 || !parentNode) {
return;
}
for (let i = 0; i < parentNode.childNodes.length; i++) {
let child = parentNode.childNodes[i];
if (child.nodeType === 3 && child.data.indexOf(keyword) !== -1) {
let newChild = document.createElement('span');
newChild.innerHTML = keyWordPreciseReplacer(escapeHtml(child.data), keyword,
`<span style="background: ${color};">` + keyword + '</span>'
);
parentNode.replaceChild(newChild, child);
} else {
htmlKeyWordHighlight(child, keyword, color);
}
}
}
/**
* 根据分词规则精准替换关键词
* @param keyword
* @param target
* @param replaceText
* @returns {*}
*/
function keyWordPreciseReplacer(keyword, target, replaceText) {
function isOver(str) {
// 根据常用分词标点符号和空格进行分词
const regStr = '[。!!??,,\\.\\s()()]';
return new RegExp(regStr).test(str);
}
let index = 0;
let targetIndex = 0;
const result = [];
const text = keyword + ' '; // 结尾添加一个空格方便isOver判断
for (let i = 0; i < text.length; i++) {
const str = text[i];
if (isOver(str)) { // text新的分词开始
if (targetIndex === target.length) { // target也刚好全匹配
result.push([index, i - target.length]);
index = i;
}
targetIndex = 0; // 重新计数
} else if (str === target[targetIndex]) {
targetIndex++; // 继续匹配
} else {
targetIndex = -1; // 本轮分词已没戏,等待下轮分词
}
}
result.push([index])
return result.reduce((acc, curr) => acc + keyword.slice(...curr) + (curr.length > 1 ? replaceText : ''), '');
}
注释写的算比较详细了。
isOver里面判断的分词的依据可能会有遗漏,后续可能动态调整,建议写到配置文件里面。
现在可没有用\b了哦。
现在我们搞个中文测试下,我们把关键词设置为我和后续,把分词的正则表达式里面加入司会,即const regStr = '[。!!??,,\\.\\s()()司会]';。
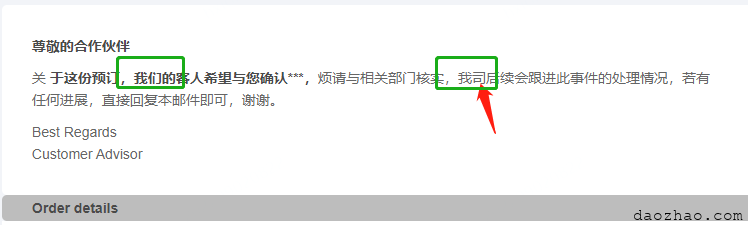
预期的效果是:我们里面的我不需要高亮,而我司的我需要高亮,同时后续也需要高亮,因为司和会代表分词结束。
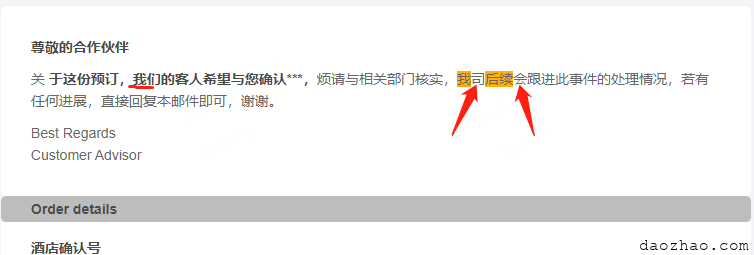
高亮结果符合预期,后期无非是遗漏了分词符号(比如、——),需要改下配置来调整正则即可。
总结
如果场景较为单一,仅需要支持英文的话,直接用\b即可,如果需要特别卷的话,那就用逐词匹配吧。
- 分类:
- Web前端