文本划词标注功能代码实现
文本划词标注功能代码实现
背景
产品需求是要支持能将一段文本选取片段并打上对应的tag,并且支持回显,同一个片段只能打一个tag(或者叫标注),tag之间不能嵌套,这算是NLP项目中一个常见功能了。
给不清楚的小伙伴简单介绍下
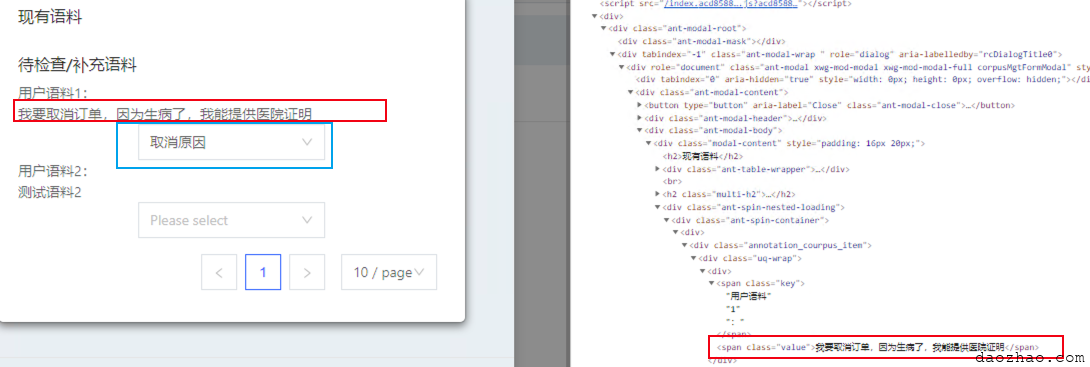
就是将上面的用户语料文本“我要取消订单,因为生病了,我能提供医院证明”中的部分文本打tag,比如将“**生病*”打上“取消原因**”的tag
最后效果如下图所示

技术实现
方案一
在功能开发初期,因为没有回显需求,当时采取了类似关键词高亮的做法来作为技术实现雏形了。
代码片段
if (range.commonAncestorContainer.nodeType === 3) {
const childNodes = parent.childNodes;
childNodes.forEach(item => {
if (item=== range.commonAncestorContainer){
const fragment = document.createElement('span');
fragment.className = 'fragment';
fragment.innerHTML = escapeHtml(item.data).replace(
new RegExp(keyword, 'g'),
`<span class="_test">
<span class="annotation_container">
<span class="annotation_target">${keyword}</span>
</span>
</span>`,
);
item.replaceWith(fragment);
}
}
)
}
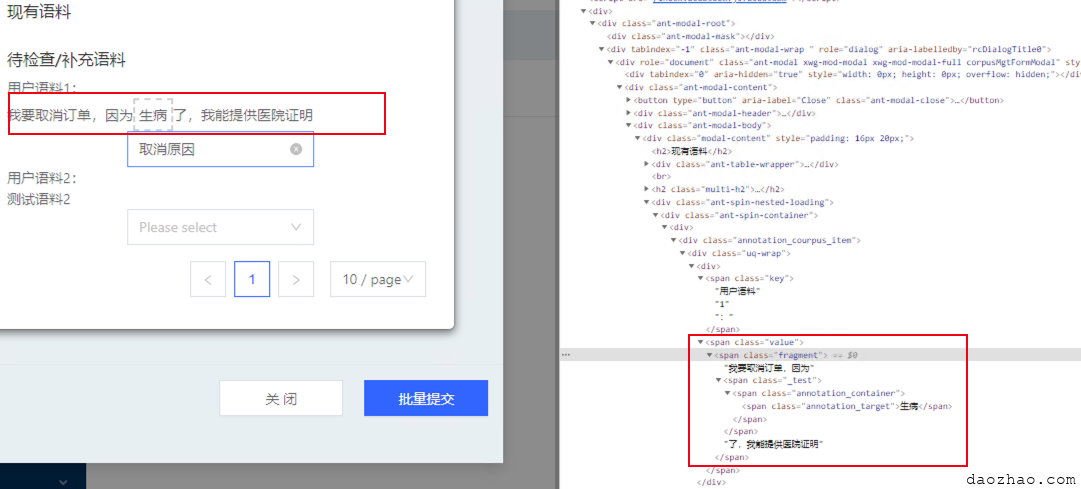
大致思路就是将目标文本(示例中的“生病”)一或多层div进行包裹(多层div包裹是为了方便实现样式),其它部分继续保留,后续再完善下如何将tag(这里的“取消原因”)也回显上去。
此思路会将原来的文本的dom结果进行严重破坏,特别打上多个tag的话,会将原来的文本分割多个相互嵌套的“fragment”。
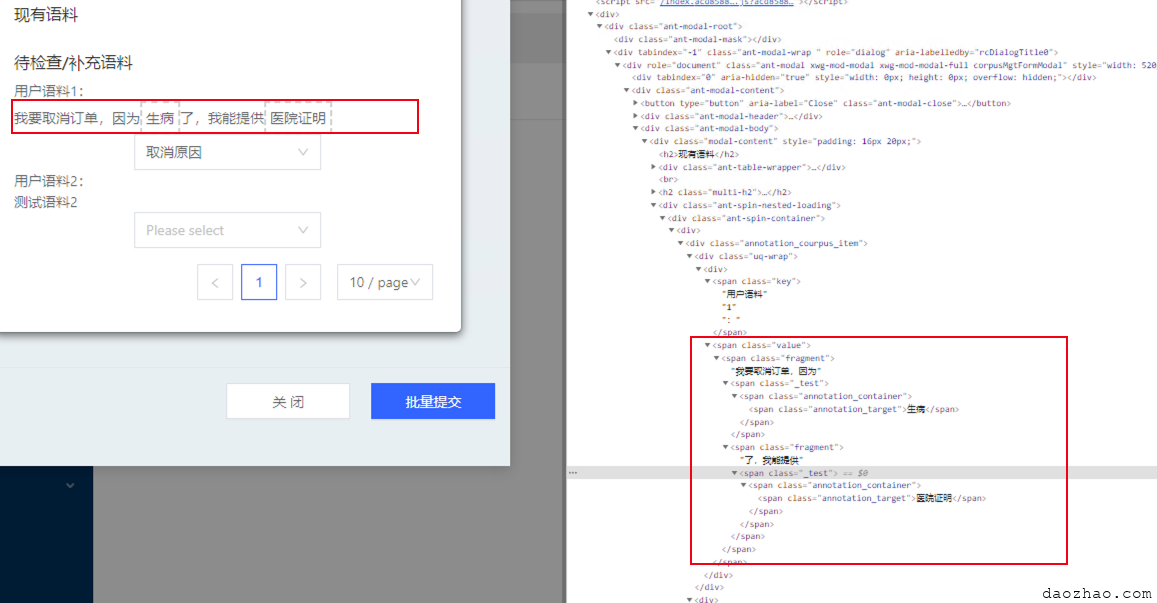
虽然视觉上看,没什么问题,但是对后续如何获取tag信息至服务端,以及如何将服务端数据进行回显制造了新的难题了。
此方案不可取,放弃。
方案二
既然需要获取tag信息以及根据服务端信息回显tag等信息,我们可以考虑将标注文本的起始坐标放置于一个数组中,返回整体文本根据该数组拆分为“原始文本片段”+“tag文本片段”的组合,然后在渲染整体文本时,根据对应的文本片段类别进行不同的渲染。
技术思路
-
首次打tag时根据选区api获取当前选中文本在原始文本的起始位置。
-
每次打tag时加一个自定义属性
data-se来记录当前被tag包裹文本在原始文本的起始位置,这样其后面的文本继续打tag时,只用根据选区api获取选中文本的起始位置+前一个tag记录的起始位置进行修正下,就能得到该文本在原始文本里面的起始位置了;其前面的文本继续打tag时,直接按照步骤1处理即可,因为此时选区api获取选中文本的起始位置和其在原始文本的起始位置相同。后续继续打tag时,因为原始文本可能因为tag的存在已经被分割成若干部分了,如果当前选中文本前面已经有tag了,此时选区api获取的起始位置指的是它在该分割片段的起始位置,而不是它在原始文本的起始位置了。
-
每次tag的起始位置信息收集至一个数组中,方便提交至服务端及回显。
-
根据tag信息数组将原始文本分成原始文本片段和tag文本片段,确保原始文本的每个文字都隶属于这两个文本片段之一
-
判断选区是否合法,支持更新、恢复选区
这样就能很好的达到前期目标效果
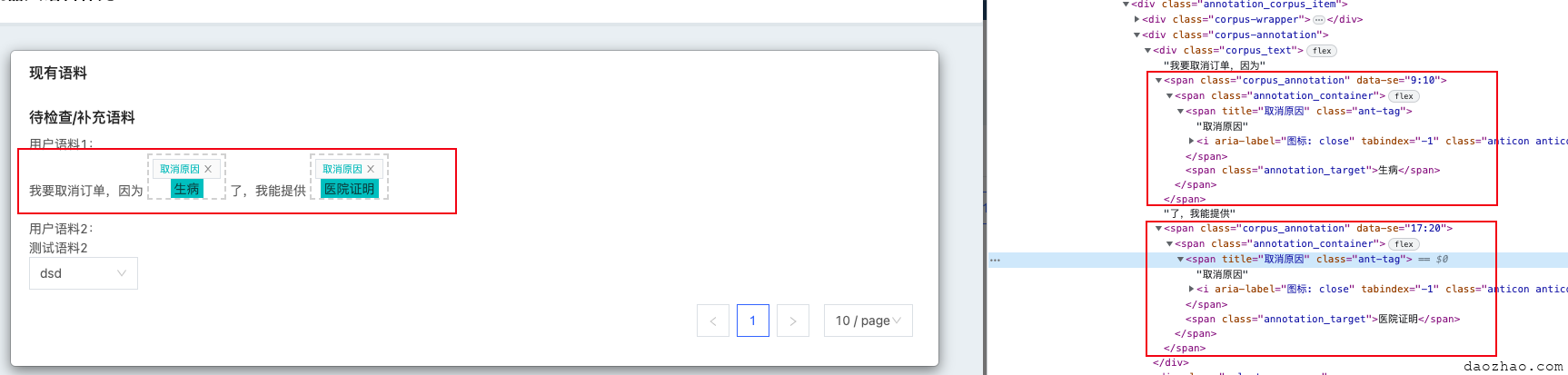
效果如下:
- 原始文本片段和tag文本片段同级展示
- 原始文本片段原样显示
- tag文本片段用
corpus_annotation容器包裹,自定义属性data-se记录tag的起始位置,:前为开始位置,:后为结束位置。 - tag文本片段中的子级节点
annotation_container(为了整体文本视觉效果加了一层dom)里面的ant-tag为tag部分,annotation_target为目标文本部分
代码片段
PS: 里面参杂有业务代码
{
updateRange(range) {
if (range !== this.state.range) {
this.setState({
range,
})
}
}
restoreRange() {
window.getSelection().removeAllRanges();
const range = this.state.range;
if (range) {
window.getSelection().addRange(range);
this.updateRange(null);
}
return range;
}
handleMouseUp(e) {
// 在语料文本区域mouseup时尝试保存选区
if (e.target.closest('.corpus_text')) {
this.updateRange(this.getValidatedRange());
}
}
getValidatedRange() {
const section = window.getSelection();
// 未选中文字 不保存
if (!section.toString()) {
return;
}
const range = section.getRangeAt(0);
const commonAncestorContainer = range.commonAncestorContainer;
// 不是选择的纯文本片段,不保存
if (commonAncestorContainer.nodeType !== 3) {
return;
}
// 选中的是 .corpus_text内的纯文本,保存
if (commonAncestorContainer.parentNode && commonAncestorContainer.parentNode.classList.contains('corpus_text')) {
return range;
}
}
// 渲染语料标注结果
annotationRender(data, isEditMode) {
const { corpus = '', slots = [] } = data;
const list = this.getCorpusSegmentList(corpus, slots);
const result = list.map(item => {
const str = corpus.slice(item.start, item.end + 1);
if (item.flag) { // 原始文本片段
return str
} else {
const matchedString = item.matchedString || '';
return (
<span className="corpus_annotation" key={`${item.start}:${item.end}`} data-se={`${item.start}:${item.end}`}>
<span className="annotation_container">
<Tag title={matchedString} closable={isEditMode}
onClose={this.handleAnnotateRemove.bind(this, data, item)}>
{matchedString}
</Tag>
<span className="annotation_target">{str}</span>
</span>
</span>
)
}
})
return (
<div className='corpus_text'>{ result }</div>
)
}
// 将语料分割成片段,并标记该片段是原始文本片段还是标记片段
getCorpusSegmentList(corpus, annotationList) {
if (annotationList.length === 0) {
return [{
start: 0,
end: corpus.length - 1,
flag: 'raw',
}]
}
const len = corpus.length;
const list = annotationList.sort((a, b) => a.start - b.start);
const result = [];
let flag = 0;
list.forEach((item, index) => {
if (item.start > flag) {
result.push({
start: flag,
end: item.start - 1,
flag: 'raw'
});
}
result.push({
...item,
})
flag = item.end + 1;
const lastIndex = list.length - 1;
if(index === lastIndex) {
if (item.end < len - 1) {
result.push({
start: item.end + 1,
end: len - 1,
flag: 'raw'
})
}
}
})
return result
}
// 标注
handleAnnotate() {
// 再次检验选区是否合法
const range = this.getValidatedRange();
if (!range) {
return;
}
const selectedString = window.getSelection().toString();
const activeTextList = this.state.activeTextList;
const idList = this.state.activeIdList;
const matchedString = activeTextList.join('/');
const prev = range.commonAncestorContainer.previousSibling;
let startOffset = 0;
let endOffset = 0;
// range记法end会比接口传参“多”1
// 比如仅选择一个字符串时,endOffset - startOffset = 1
// 而接口记法start和end是相等的
// 故需要区分情况调整偏移量
// 前面有标注痕迹
if (prev && prev.nodeType === 1 && prev.classList.contains('corpus_annotation')) {
const datasetStr = prev.dataset['se'] || ''
if (datasetStr) {
const [start, end] = datasetStr.split(':').map(Number);
startOffset = end + 1;
endOffset = end;
}
} else {
startOffset = 0;
endOffset = -1;
}
const targetCorpus = this.props.data;
if (!targetCorpus.slots) {
targetCorpus.slots = [];
}
if (idList.length > 1) { // 包含实体
targetCorpus.slots.push({
start: range.startOffset + startOffset,
end: range.endOffset + endOffset,
selectedString,
matchedString,
value: activeTextList[1], // 实体值
})
} else { // 仅含有词槽
targetCorpus.slots.push({
start: range.startOffset + startOffset,
end: range.endOffset + endOffset,
selectedString,
matchedString,
id: idList[0], // 词槽id
})
}
this.props.setParentState({
allDailyData: this.props.allDailyData.slice(),
})
}
}
总结
- 方案一有点类似jQuery时代的做法,简单粗暴,只适合一次性的视觉展示,无需获取tag信息的场景使用
- 方案二类似React的数据驱动试图的方式来实现,只用专注于数据即可
- 分析此类需求实现时应该透过表象看到本质,优先考虑利用数据驱动试图的思路完成
- 分类:
- Web前端